字符串输入节点。
字符串转曲线*将字符串转换为曲线实例。字符串中使用的每一个独特的字符都会被转换为曲线一次,而该字符的进一步使用则是同一几何图形的更多实例。
这使得处理输出的几何图形非常有效,因为每个独特的字符只需要处理一次。然而,这意味着对于同一个字符的每个实例,其结果都是一样的。要单独处理每个字符,可以使用 实例项 。
Tip
插槽检测 可以用来查看节点被评估时使用的字符串输入值,方法是将鼠标放在插槽上。
输入
- 字符串型
基础字符串输入。
- 尺寸
每个字符的大小。其他输入的值由这个值缩放。
- 字符间距
字符间距(字距)缩放的系数。
- 单词间距
在 X 轴上缩放单词之间空格的因子。
- 行间距
输出中不同行之间的距离。由 尺寸 的输入进行缩放。
- 宽度
每行的最大宽度,不过个别字不会被包起来。
- 矩形盒高度
文本所有行的最大高度。
属性
- 字体
用作曲线,字体和曲面物体的数据。
- 溢出
- 溢出
将文本换行到 文本框宽度 处。
- 缩放至适应
缩放文字大小以适应 文本框宽度 和 文本框高度 。
- 截短
只输出符合宽度和高度的文本字符,基于 Size 的输入。字符串中任何不适合的部分会被移到 Remainder 输出。
- 对齐
- 左
文本对齐到左边。
- 中心
文本对齐到中间。
- 右
文本对齐到右边。
- 左右对齐
文本左右对齐
- 分散对齐
以相等的字符间距将文本向左和向右对齐。
- 对齐Y轴
- 文本与顶部基线对齐。
文本与顶部基线对齐。
- 顶视图
文本对齐到顶部。
- 文本对齐到中间。
文本对齐到中间。
- 将文本与底部基线对齐。
将文本与底部基线对齐。
- 底视图
文本底部对齐。
- 轴心点
控制每个字符上的输出 支点 的位置。
- 中点
将枢轴点放在每个字符边界的中心。
- 在3D视窗的左上角,显示活动物体名称和帧数。
将支点放在每个角色的边界的左上方。
- 顶
将支点放在每个角色的边界顶部的中间位置。
- 在右上角的搜索栏中,输入
Power Sequencer。 将支点放在每个角色的边界的右上方。
- 左下角
将支点放在每个角色的边界的左下方。
- 移动到第 12 帧,并在底部中心中绘制一个挤压的球(breakdown,间断帧)。
将支点放在每个角色的边界的中间和底部。
- 右下角
将支点放在每个角色的边界的右下方。
输出
- 实例项
实例项
- 将第一个输入值被第二个输入值相除,输出所得结果的余数值。(备注:取模运算( "Modulus Operation")和取余运算( "Remainder Operation ")两个概念有重叠的部分但又不完全一致。主要的区别在于对负整数进行除法运算时操作不同。取模主要是用于计算机术语中。取余则更多是数学概念。参看百度百科 "取模运算" )
文本中不适合 文本框高度 和*文本框宽度 输入所描述的框的部分。只在 *Truncate 溢出模式下使用。
- 线形
一个属性字段,包含文本布局中每个字符行的索引(在 instance domain)。
- 轴心点
输出每个实例的本地空间中 支点 下拉所描述的位置。
示例
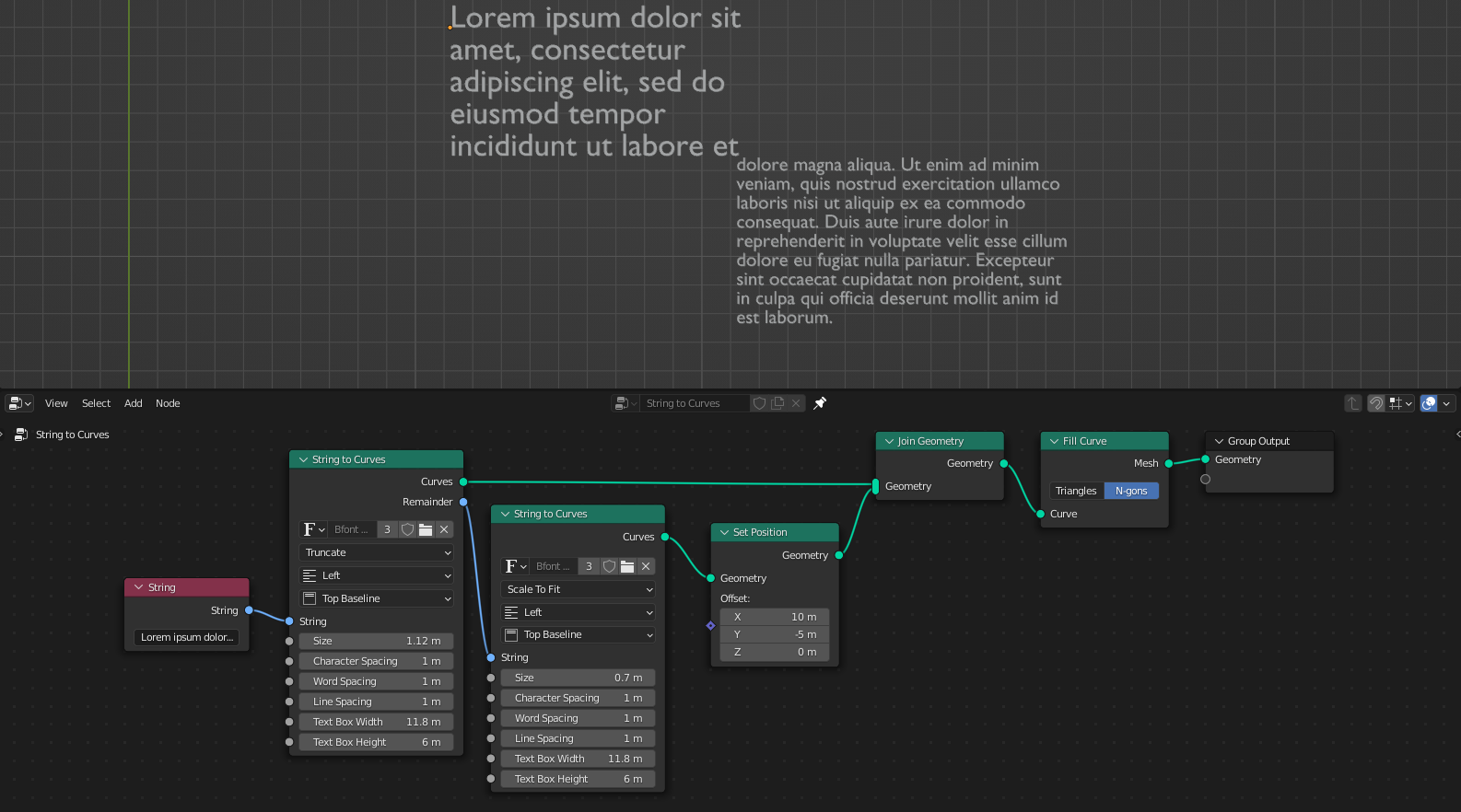
该节点可用于制作溢出的文本框。这里,不适合第一个节点的固定大小的文本框的文本被传递到一个单独的*String to Curves*节点。最后用一个*Scale to Fit*节点添加。