Поля (fields)¶
По сути, поле – это функция: набор инструкций, которые могут преобразовывать произвольное количество входов в один выход. Затем результат поля может быть вычислен много раз с различными входными данными. Они используются во всех геометрических нодах, чтобы обеспечить расчёты, которые дают разные результаты для каждого элемента (вершины меша, грани и т. д.).
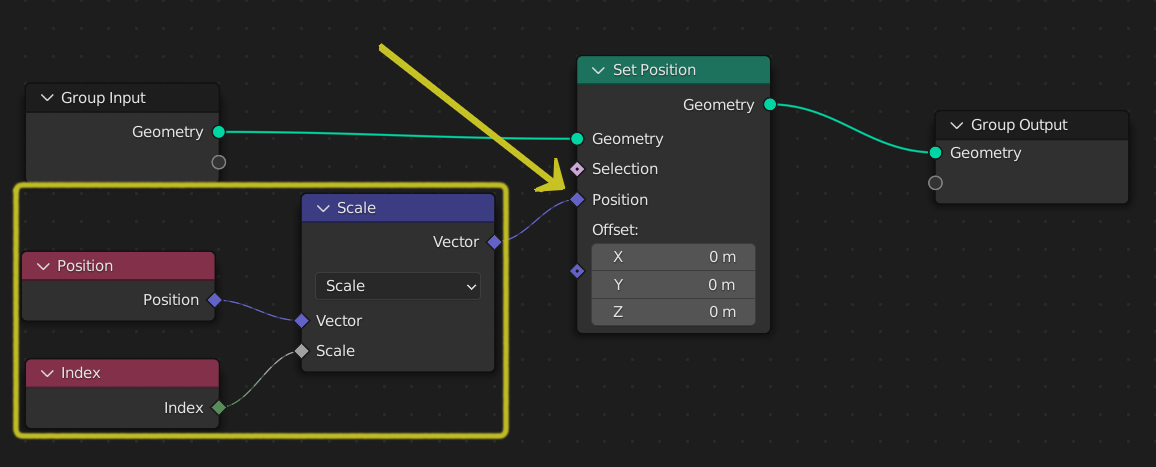
Поле ввода ноды.¶
Например, на рисунке выше, – поле, соединённое с нодой „Set Position“, зависит от двух входов, „Position“ и „Index“, и преобразует их в вектор с помощью единственной инструкции.
Отображение поля¶
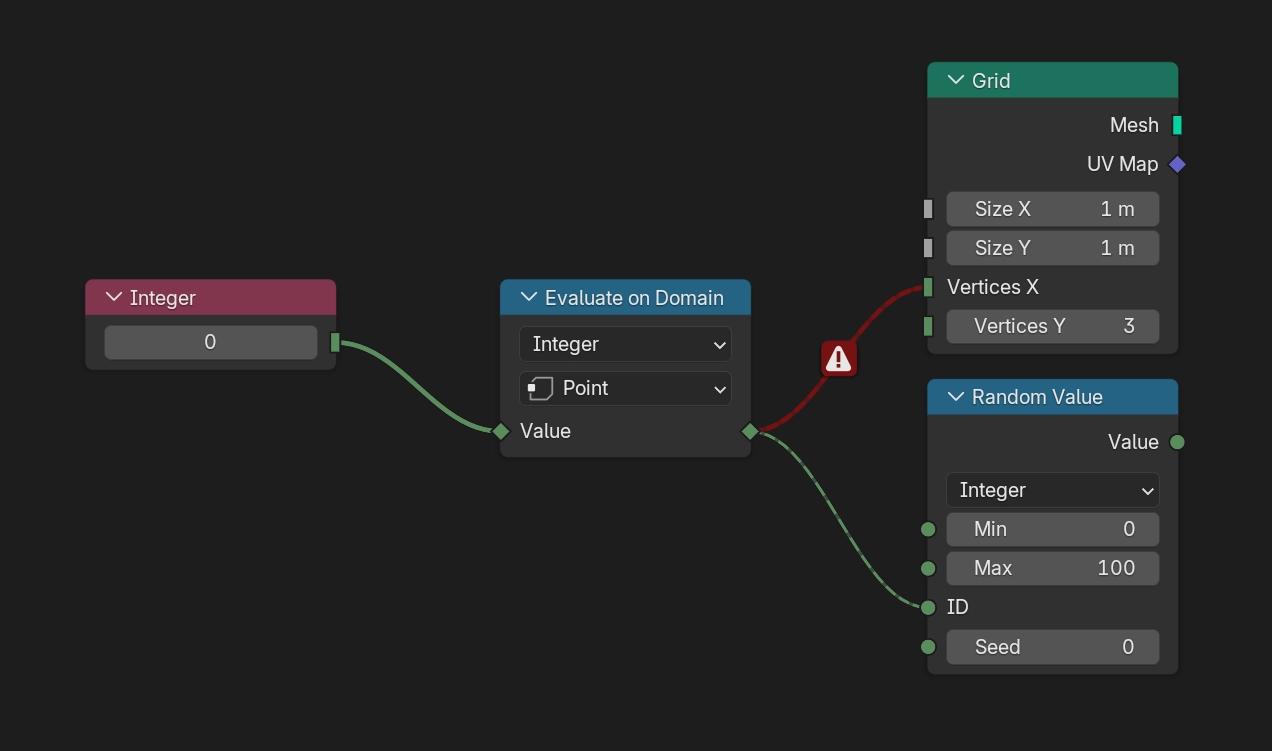
If a node connection is coming from a field socket, it will be drawn as a dashed line. Otherwise, it will be drawn as a solid line instead.
If you make the mistake of connecting a non-field socket to a field socket, the connection will be drawn as a solid red line indicating that there is an error.
Совет
Часто требуется извлечь из поля единичное значение. Хотя концептуально не имеет смысла простое преобразование поля в единичное значение, для извлечения единичного значения из поля, оценённого по геометрии – можно использовать ноду „Sample Index“ или ноду „Attribute Statistic“.
Типы нод (node types)¶
Ноды можно разделить на две категории: ноды потока данных, которые обычно передают геометрию, и ноды полей, которые работают с данными для каждого элемента. Ноды поля могут быть входными нодами, которые вносят геометрические данные в нодовое дерево, или функциональными нодами, которые работают с этими данными.
Ноды потока данных¶
Ноды с входной и выходной геометрией почти всегда будут нодами потока данных. Это означает, что они фактически изменяют данные геометрии, которые будут выводиться модификатором „Geometry Nodes“.
Функциональные ноды¶
Ноды с ромбовидными входами и выходами являются нодами поля и напоминают инструкции, которые будут оцениваться нодами потока данных. Примерами функциональных нод являются математические ноды, а также более сложные ноды, такие как нода „Geometry Proximity“.
Ноды ввода (input nodes)¶
Входные ноды предоставляют данные для процесса оценки поля. Сами по себе они ничего не значат; они должны быть оценены в контексте ноды потока данных (геометрия), чтобы фактически вывести значение. Примерами входных нод являются встроенные входные ноды атрибутов, такие как нода „Position“ и нода „ID“, а также ноды выделения, такие как нода „Endpoint Selection“.
Вводные поля также могут поступать от других нод, обрабатывающих геометрию, таких как нода „Distribute Points on Faces“, в форме анонимных атрибутов.
Контекст поля¶
Все ноды полей работают в контексте ноды потока данных, с которой они соединены. Контекст обычно состоит из типа компонента геометрии и домена атрибутов, поэтому он определяет какие данные извлекаются из входных нод.
Одним из распространённых заблуждений является то, что одно и то же дерево нод полей, используемое в нескольких местах, будет выводить одни и те же данные. Это не обязательно верно, потому что дерево нод полей будет оцениваться для каждой ноды потока данных, потенциально извлекая данные из другой или изменённой геометрии.
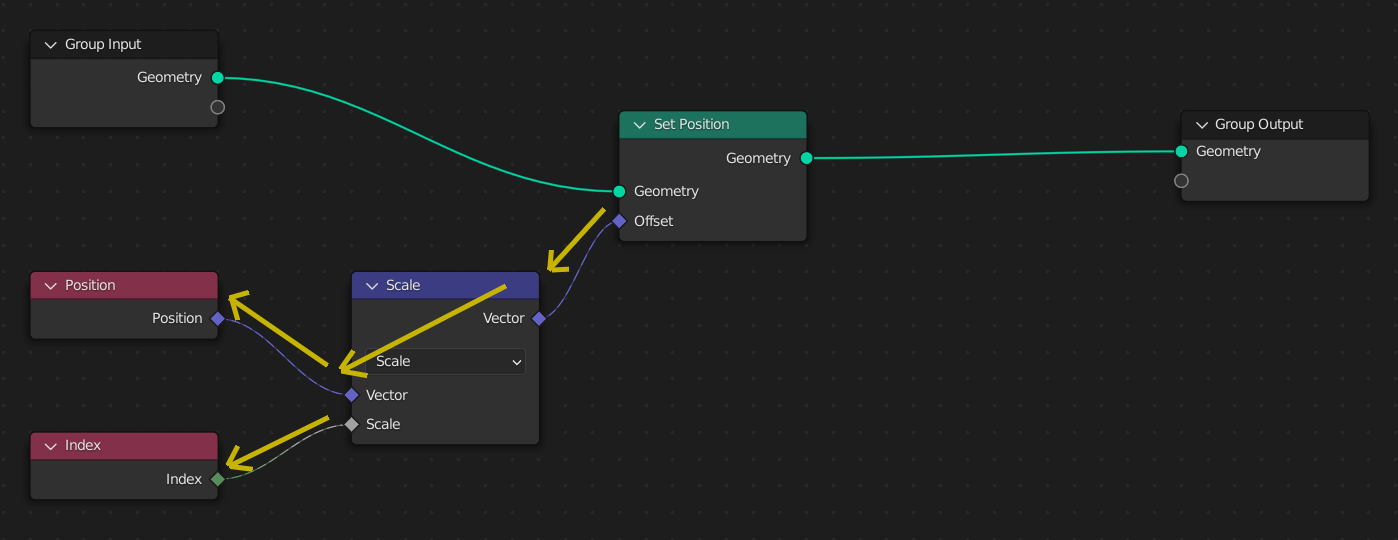
Здесь поле ввода ноды „Set Position“ оценивается один раз. Чтобы оценить поле, нода проходит назад, чтобы получить входные данные из нод ввода поля.
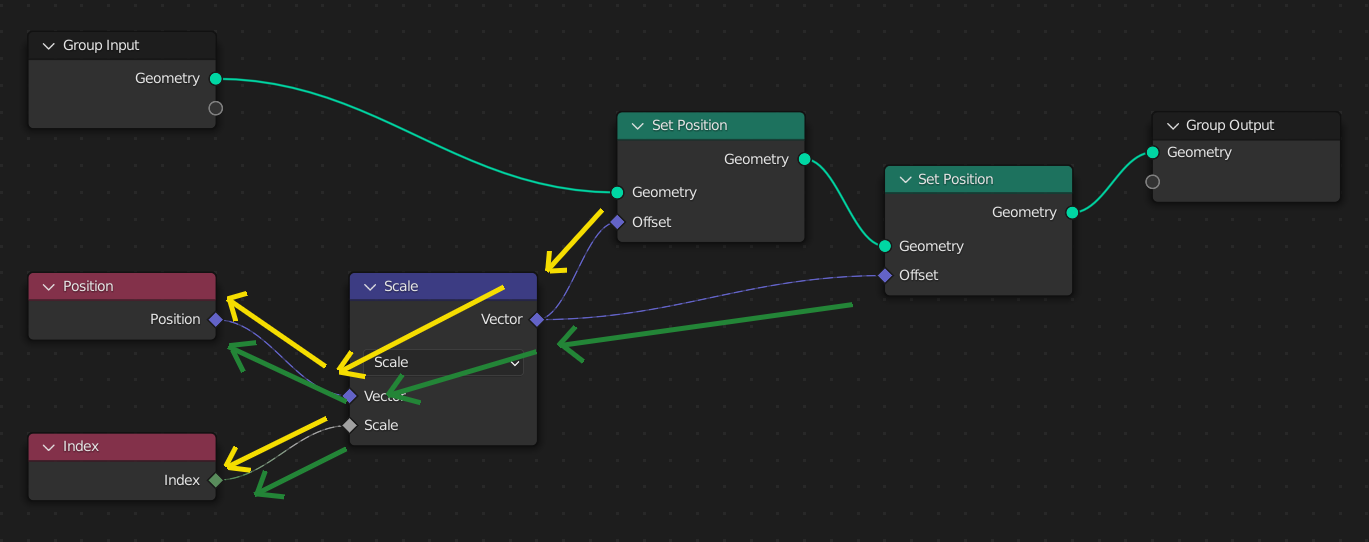
Когда добавляется вторая нода „Set Position“, одно и то же дерево нод полей оценивается дважды, по одному разу для каждой ноды потока данных. Во второй ноде „Set Position“ результаты будут другими, так как её входная геометрия уже будет иметь изменённое положение из первой ноды.
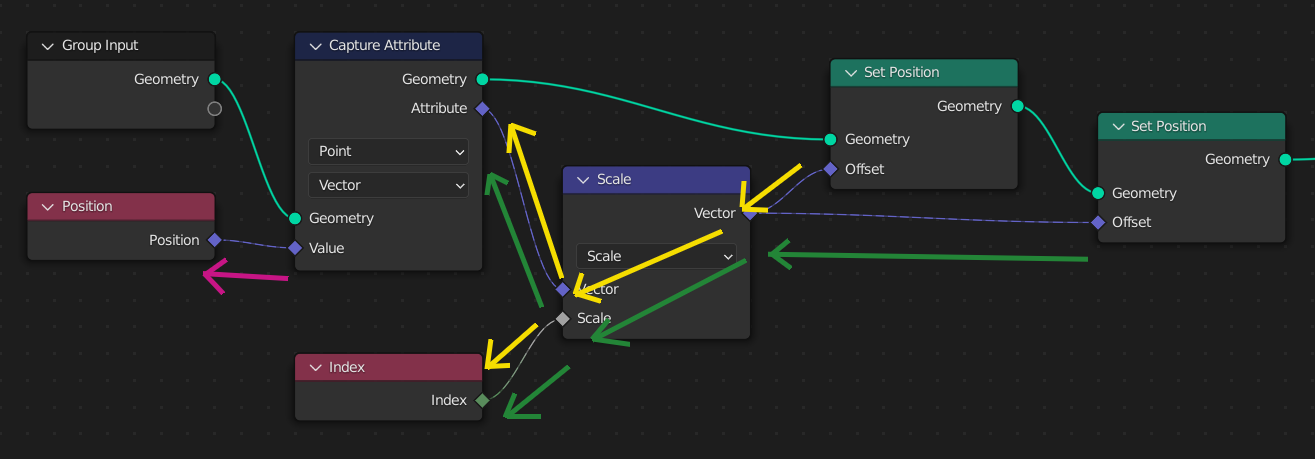
Однако часто необходимо использовать одни и те же значения поля даже после изменения геометрии. Нода „Capture Attribute“ оценивает поле, копируя результат в анонимный атрибут геометрии.
Здесь нода „Capture Attribute“ хранит копию исходного „положения“. Обратите внимание, что оценка ввода поля ноды „Capture Attribute“ – это совершенно другой шаг. Позже поля ввода для нод „Set Position“ используют не фактическое „положение“, а его копию анонимного атрибута.